
La programmation informatique (et surtout, sa difficulté intrinsèque) a toujours suscité de grands débats et de grandes prédictions : rappelez-vous ce qu’on attendait de l’approche objet dans les années 90 et du peu qu’on en a finalement obtenu sur ce plan.
Mais, même en tenant compte de ces déceptions passées, on sent que les choses sont de nouveaux prêtes à bouger dans ce secteur. Nous avions déjà largement évoqué les environnements “low code” dans une précédente chronique (datant de juin 2018, voir Comment choisir un outil de développement “Low-code”), voyons aujourd’hui comment ont évolué ces nouvelles offres. Tout de suite, on constate qu’on va dans le sens d’un élargissement des usages et des populations qui sont désormais de plus en plus nombreuses à être concernées et visées par cette seconde vague des outils NoCode/LowCode. C’est d’ailleurs ce qu’on a toujours constaté dans l’évolution de l’informatique : chaque étape de l’histoire technique a été accompagnée d’un élargissement des usages et des populations concernées (utilisateurs et personnel technique).
La première vague adressait -logiquement- la programmation d’applications
La première vague des outils NoCode/LowCode s’adressait aux “Citizen Developers” et visait à développer plus facilement (et donc plus rapidement) des applications classiques, principalement en s’appuyant sur l’interface Web et en permettant la saisie et la gestion des données. Cette cible initiale relativement limitée était parfaitement logique car, reconnaissons-le, le développement d’applications (y compris les applications relativement “simples”) a toujours été une “épine dans le pied” des informaticiens et des DSI.
Les logiciels dévorent le monde, mais sont toujours codés à l’ancienne…
Écrire du code classiquement est toujours une opération pénible, obscure et peu productive (en plus d’être peu fiable). Et pourtant, le logiciel est désormais omniprésent. Marc Andreessen est connu (entre autres) pour son expression : “Les logiciels dévorent le monde”. Et, effectivement, l’explosion récente des applications Web et mobiles a façonné tous les aspects de nos vies modernes : notre travail, nos communications, nos transports, nos systèmes financiers et même notre nourriture. N’est-il pas étrange qu’une si grande partie de notre monde soit constituée par le travail d’un si petit groupe de spécialistes ?
Pire, celui-ci continue à travailler “à l’ancienne” comme des moines copistes du Moyen-Age juste avant l’invention de l’imprimerie…
Multiplier avec des chiffres romains ?
Bret Victor, un ancien designer chez Apple, fait une excellente analogie pour décrire cette anomalie en s’appuyant sur l’évolution des Mathématiques courantes :
“Avez-vous déjà essayé de multiplier les chiffres romains ?
C’est ridiculement difficile. C’est pourquoi, avant le XIVe siècle, tout le monde pensait que la multiplication était un concept incroyablement difficile, réservé à l’élite des mathématiciens. Puis les chiffres arabes sont arrivés et nous avons découvert que même les enfants de sept ans peuvent très bien gérer la multiplication. Ce concept n’était pas difficile à résoudre : le problème était que les nombres, à l’époque, avaient une mauvaise interface utilisateur.”
Autre exemple pour comprendre l’importance cruciale de l’interface : les premiers traitements de texte
À l’époque des premiers traitements de textes (à la fin des années soixante-dix sur PC et un peu avant sur machines dédiées), il fallait coder les attributs que vous vouliez voir apparaître (gras, italique, souligné, etc.) sans que vous puissiez voir le résultat (un mot ou une phrase mise en gras par exemple) à l’écran. Il fallait imaginer comment le code allait être interprété par l’ordinateur, donc “jouer l’ordinateur dans votre tête” ou imprimer le texte au fur et à mesure de sa rédaction pour voir ce qu’il rendait.
Tout a changé avec les traitements de textes WYSIWYG (“ce que vous voyez est ce que vous obtenez”) : il suffisait alors de mettre un passage en italique pour que les lettres s’inclinent. Juste en regardant votre document, vous étiez capable de voir ce qui n’allait pas dans la mise en forme de votre texte. Même chose avec le HTML des premiers temps du Web : avant que WordPress (et d’autres) soient là pour faciliter la mise en place d’un site, le HTML n’était pas trop complexe mais quand même pénible à utiliser “brut”…
La version logicielle des chiffres romains
Nous buttons sur la même difficulté avec les processus traditionnels de développement des logiciels (en clair, le coding) : API cryptiques, points-virgules à placer parfaitement, paramètres de ligne de commande à ordonner soigneusement ou même trois façons (différentes !) d’utiliser le signe égal. C’est clairement la version logicielle des chiffres romains. Le développement logiciel a clairement besoin d’une nouvelle interface s’il veut sortir du cercle étroit des moines-copistes de notre époque (dans une large mesure, les programmeurs de code actuels sont comme les moines copistes d’antan : les seuls capables de s’astreindre à un travail aussi difficile et fastidieux).

Une première vague désormais très fournie
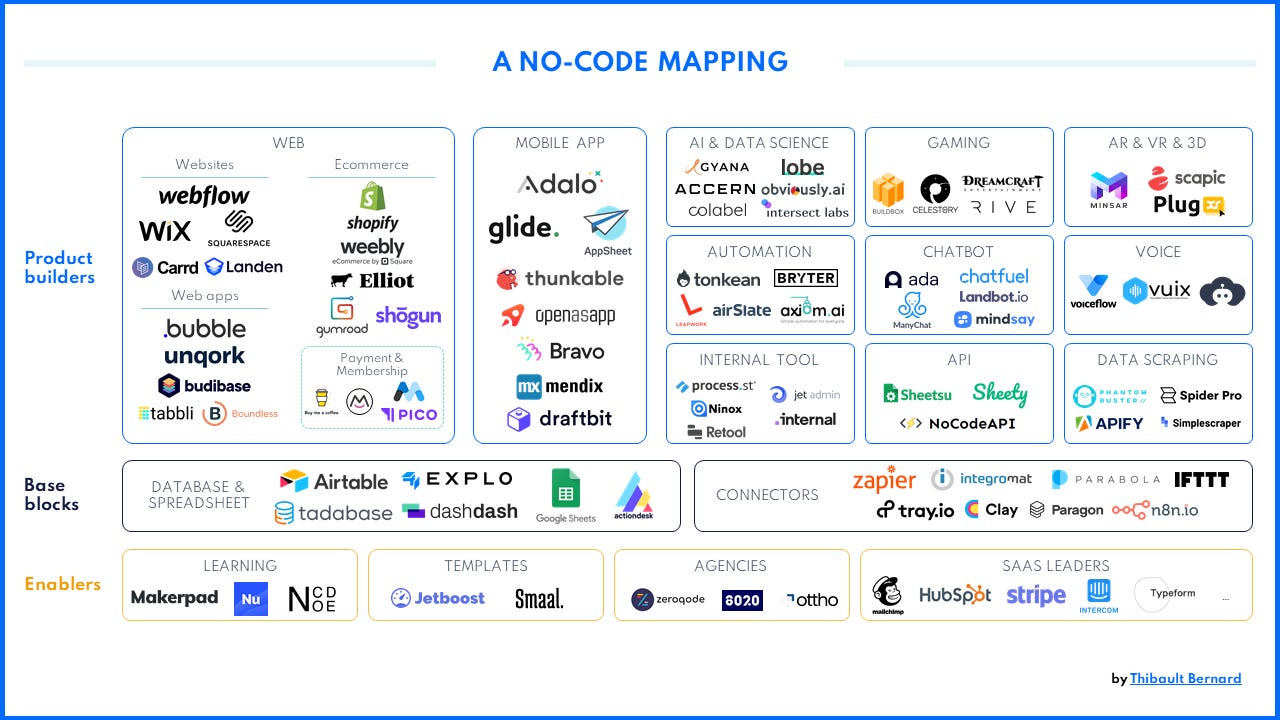
La première vague des outils LowCode/NoCode était constituée des pionniers comme AirTable, Coda et Quickbase (entre autres, les lister tous ici serait inutile) qui apportaient des solutions de types “bases de données” à un public qui n’était plus restreint aux spécialistes du domaine. Le dynamisme de la première vague n’a pas faibli et les acteurs sont désormais tellement nombreux dans ce domaine (y compris des éditeurs européens avec quelques français intéressants dans le lot !) qu’il serait vain d’essayer de les citer tous. Certains s’y essayent pourtant graphiquement et cela donne ça :

Ou ça :

Et il existe même un site de référence (en français !) sur le sujet https://quels-outils-nocode.fr/ très bien fait et assez complet.
Les GAFAM s’y mettent aussi
Les grands acteurs commencent aussi à s’y mettre, plus ou moins sérieusement mais on sent que ça bouge aussi de leur côté. Amazon propose désormais Honeycode et Google pousse AppSheet alors que Microsoft se contente encore d’un Powerapps assez confus.
C’est parce que ce mouvement s’attaque à une lacune persistante de l’informatique (la difficulté de programmer) qu’il bénéficie d’une telle dynamique. Ce n’est pourtant pas la première fois que ce “bastion” (la programmation) essuie des attaques venant de “nouveaux acteurs” : depuis les années 90, les tentatives ont été nombreuses avec, à chaque fois, des noms différents (L4G, AGL, etc.). Certains pensent que “la programmation ne sera jamais simple” alors que d’autres soutiennent que la difficulté intrinsèque de cette discipline n’est qu’une anomalie circonstancielle et qu’elle peut être surmontée.
Des chiffres qui confirment l’engouement
Les chiffres concernant la taille du marché de ces outils des récentes années montrent une progression intéressante mais les prévisions futures sont encore plus significatives : les analystes de MarketsandMarkets prévoient un essor très marqué avec un triplement du chiffre d’affaires sur ce segment !
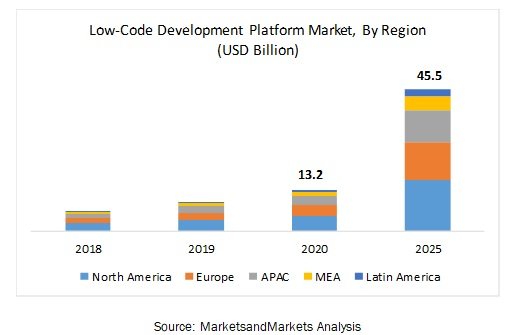
Si on en croit les prévisions de ces analystes, le secteur des outils LowCode/NoCode va passer de $13,2 milliard en 2020 (des chiffres qui ne sont pas encore consolidés, évidemment) à $45,5 milliards en 2025… On comprend mieux pourquoi les GAFAM se sont empressés de rejoindre cette scène !
Mais l’enjeu du NoCode/LowCode ne se limite pas au développement des applications comme nous allons le voir maintenant.
La seconde vague déborde de la programmation…
En effet, ce n’est pas cette multiplication des offres dans ce créneau du développement d’applications mis à la portée du “citizen developer” qui est significatif de cette “seconde vague”… Désormais, l’offre LowCode/NoCode déborde largement des outils de développement et concerne quasiment tous les domaines : middlewares, RPA, API, transfert et analyse des données et ainsi de suite.
Des entreprises comme Glitch, Zapier (qu’on a déjà évoquées à https://www.redsen.com/fr/inspired/tendances-decryptees/les-middlewares-cloud-pour-une-integration-no-code), Parabola, Integromat et IFTTT tentent de permettre à quiconque de faire des choses que seuls les “vrais” développeurs et administrateurs systèmes pouvaient faire jusqu’à présent. En gros, on peut dire que le NoCode/LowCode ne se contente plus de faire naître des “citizen developer” mais qu’il rend la fonction “DevOps” (très à la mode en ce moment) également plus accessible !
Le domaine “systèmes” se rend plus accessible
Cet élargissement vers des outils considérés comme relevant du domaine “systèmes”, habituellement opérés par des intervenants très qualifiés et très spécialisés peut s’expliquer naturellement : maintenant que l’offre logicielle se développe principalement sur le cloud, les interfaces d’usages sont obligées de suivre… basées sur le Web, elles sont forcément plus faciles à manipuler et donc plus accessibles. C’est sans doute (en partie) vrai mais ce n’est qu’une explication partielle. L’autre force motrice réside dans la réalisation que le développement d’applications ne se limite pas à la partie “cliente” visible par les utilisateurs finaux. Pour obtenir un vrai résultat, il faut bien plus qu’un frontal qui va accéder à une base de données unique. Du middleware va être nécessaire pour rassembler des sources de données différentes et de l’automatisation (RPA) interviendra afin d’unifier tout cela.
Un environnement d’exécution sécurisé :
Un autre avantage qui joue en faveur de ces nouveaux environnements et qui n’est pas souvent (pas assez) mis en avant, est la sécurité d’exécution. Contrairement à ce qui était proposé dans les années 90 par les éditeurs de L4G (Powerbuilder, Delphi, …), on ne se contente pas ici d’un environnement intégré de développement (IDE), mais d’une plateforme globale qui va permettre d’héberger, d’exécuter les applications, de gérer les montées de versions et les droits d’accès des utilisateurs…
En caricaturant, on pourrait comparer ces plateformes à ce que l’on avait avec les mainframes (en regroupant tous les composants, l’OS et le moniteur transactionnel) mais avec la simplicité des architectures Web et Cloud.
Sur les plateformes les plus évoluées, nous avons à notre disposition l’ensemble des outils permettant de traiter la chaîne complète (de la définition des besoins jusqu’au monitoring en production). On voit ainsi disparaître plusieurs des gros risques du shadow IT :
- L’exploitation,
- Le déploiement,
- La sécurité.
Attardons-nous sur ce dernier point. Les entreprises dépensent des montants colossaux pour sécuriser leurs SI (cf. article sécurité). Mais dépenser des montants importants pour la porte blindée alors qu’une des fenêtres est ouverte (mon tableau Excel qui circule par mail…) est bien évidemment inacceptable. C’est pourtant la réalité rencontrée sur le terrain.
Ce risque diminue considérablement avec ces nouveaux environnements (puisque les données restent dans un environnement contrôlé et administré par la DSI). Pour compléter, parlons aussi de la qualité des données.
Il est très rare qu’une application puisse fonctionner de manière complètement autonome. En règle générale, elle s’appuie à minima sur des référentiels qui doivent être alimentés (et proviennent d’autres briques du SI). Dans un environnement intégré au SI, on peut mettre en place des connecteurs qui permettent d’avoir accès à des données de qualité et en permanence à jour. Dans le cas du shadow IT, on va (trop souvent) se contenter de copies sauvages de données… On le voit, les environnements NoCode/LowCode gagnent sur tous ces points cruciaux.
Compartimentalisation en cours
Il est probable qu’on va assister à une compartimentalisation du développement en de nombreuses couches, de la plus pointue (la programmation système) qui va sans doute rester basée sur l’écriture de code (avec des langages traditionnels où le C tient encore sa place) à la plus accessible où ces nouveaux environnements vont se disputer les faveurs de ces légions (encore à venir) de “citizen developers”. Les couches intermédiaires déjà connues vont elles rester plus ou moins à l’identique avec les mêmes outils et les mêmes pratiques.
Pas un remplacement
Mais l’erreur serait justement de voir cette nouvelle vague comme un remplacement. Il ne s’agit pas de se débarrasser du coding mais plutôt de le compléter. Les développeurs (DevOps ou pas) capables de coder ne sont pas assez nombreux pour nos besoins futurs et il nous faut donc une nouvelle génération de programmeurs et en grand nombre. C’est donc précisément envers cette nouvelle génération que ces outils sont destinés. La notion de “citizen developer” commence justement à apparaître et elle arrive en même temps que ce renouvellement de l’offre d’outils. La logique est la suivante : plutôt que de vouloir nier l’existence du “shadow-IT”, mieux vaut accompagner le mouvement avec des environnements appropriés.
Une approche en phases successives
Il semble donc bien que cette seconde génération ait réussi à s’installer durablement dans notre paysage informatique et à changer nos habitudes pour de bon. Les projets de développement d’applications vont donc être à géométrie variable désormais grâce à une panoplie d’environnement élargie. Lors des premières phases, on va avoir recours à un environnement NoCode ultra-accessible afin d’impliquer au maximum les utilisateurs (et même les laisser-faire dans le meilleur des cas !). Lors des phases suivantes, on va consolider le projet en s’appuyant éventuellement sur un environnement LowCode un peu plus sophistiqué (moins accessible mais avec un potentiel technique plus profond). Enfin, on va faire appel à des environnements “purement” destinés aux codeurs quand on voudra développer les extensions et l’éventuelle “tuyauterie” nécessaire à la finalisation du projet (middleware, API).
Grâce à l’accessibilité de ces nouveaux outils, nous avons l’opportunité de créer un nouveau dialogue avec les utilisateurs : en combinant ce que nous indique les “projets souterrains” du shadow-IT avec la capacité de prototypage rapide des offre NoCode/LowCode, on aura plus de chances de viser juste et d’exécuter rapidement afin de maintenir et d’enrichir ce dialogue indispensable avec les utilisateurs et ce tout au long des projets. En faisant ainsi, on va enfin réduire le taux d’échec aberrant des projets informatiques !



{kind=link}
Toujours 10 ans d’avance , ou peut-être plus.
Merci