Avant de commencer, précisons qu’il est toujours plus facile de dire le « quoi » que le « quand ». Par exemple, prédire que les voitures électriques (avec l’aide de l’hydrogène ou pas) vont prendre le dessus sur les voitures à moteur thermique est facile, il est beaucoup plus difficile de préciser quand cela va finalement arriver (réponse : pas à court terme !).
Donc, le côté délicat de l’exercice du jour est de préciser ce qui va arriver ou ne pas arriver durant l’année 2020, nuance importante…
Rien de sensationnel ici donc : les événements qui vont se précipiter en 2020 étaient déjà en préparation lors de 2019, forcément. Il ne s’agit donc que de tendances qui deviennent progressivement des réalités puis des évidences.
Vous allez sans doute trouver que mes prévisions sont plutôt pessimistes (je me vois comme un réaliste…) mais, hey, si c’est pour lire la même chose qu’ailleurs, quel intérêt ?
Donc, disons-le clairement : ce que vous lirez ici, vous ne le retrouverez pas ailleurs !
1- Voitures autonomes, pas demain ni après-demain
Puisqu’on évoquait les voitures électriques, restons sur ce sujet « de la bagnole » pour préciser que les voitures autonomes, totalement autonomes, vont continuer à se faire attendre. La voiture autonome de niveau 5 n’est pas pour 2020 ni même sans doute pour les années suivantes. Allez, gageons qu’il faudra encore dix ans (oui, 10 ans !) pour atteindre ce niveau. Et encore, il y a aura des restrictions géographiques : autonome oui, mais pas partout
Plus sur ce sujet => https://www.redsen.com/fr/inspired/tendances-decryptees/2-voitures-autonomes-ou-les-limites-de-lapprentissage-profond
2- La blockchain va caler
Encore un buzz récent et injustifiable qui va se dégonfler. Imaginer que la blockchain peut être tout pour tous relève essentiellement d’une naïveté confondante ou d’une mauvaise foi très solide (et, dans les deux cas, c’est grave…). C’est durant cette année 2020 qu’il sera définitivement clair que les applications basées sur les différentes formes de blockchain disponibles sont 1) difficile à développer et 2) encore plus délicates à faire fonctionner… Forcément, les bases de données distribuées à grande échelle ne sont pas un socle viable pour des applications transactionnelles et le bon sens va finir par nous faire l’admettre.
Plus sur ce sujet => https://www.redsen.com/fr/inspired/tendances-decryptees/il-est-temps-de-se-montrer-enfin-raisonnable-vis-a-vis-de-la-blockchain
3- Vieux acteurs, l’heure du déclin a sonné
Pour la vieille garde, c’est le dernier tour de piste !
IBM, Oracle, Intel, HP sont les morts-vivants de cette année : déjà dépassés, en passe d’être oubliés, n’ayant quasiment plus d’influence sur rien, ils tentent de ramasser ce qui peut encore l’être sur le dos des organisations clientes les plus crédules ou les plus timides.
Plus sur ce sujet => https://www.redsen.com/fr/inspired/tendances-decryptees/une-page-se-tourne-les-anciens-leaders-laissent-la-place-aux-nouveaux-acteurs-pourquoi
https://www.redsen.com/fr/inspired/tendances-decryptees/le-declin-dintel-est-amorce-par-tsmc
https://www.redsen.com/fr/inspired/tendances-decryptees/la-prochaine-disparition-dibm
4- Les GAFAM : on va passer d’un quintette à un trio
Le groupe des leaders va continuer à dominer la scène, mais il va se restreindre par la même occasion. Apple et Facebook vont se faire exclure de ce groupe et vont ruminer leurs déboires dans leurs coins. Facebook va avoir du mal à remonter la pente après une année 2019 vraiment désastreuse (en termes d’image sinon de résultats) et Apple va payer cher sa monoculture centrée sur l’iPhone alors que le marché est en train de se retourner.
Plus sur ce sujet =>
https://www.redsen.com/fr/inspired/tendances-decryptees/apres-les-gafam-et-les-batx-quoi
5- La 5G va prendre son temps
Le déploiement de la 5G va demander quelques mois, au minimum. Inutile donc d’en attendre beaucoup en 2020. De plus, sa mise en œuvre sera graduelle : tous les bénéfices de cette nouvelle génération ne seront pas disponibles tout de suite.
Plus sur ce sujet => https://www.redsen.com/fr/inspired/tendances-decryptees/ou-nous-emmene-la-5g
6- L’ambient computing s’impose progressivement
On parle d’une nouvelle tendance avec l’Edge Computing, mais c’est plutôt l’essor de l’IOT qui va déterminer la nouvelle ambiance qui débute dès cette année. J’ai utilisé le terme “ambiance” à dessein, car c’est bien vers cela que nous allons : une informatique tellement omniprésente qu’elle fait désormais partie intégrante de notre environnement de vie et de travail. Tout cela n’est pas nouveau, c’est simplement l’étiquette qui change : ambient computing, voilà ce qui a les plus grandes chances de s’imposer à partir de 2020.
Plus sur ce sujet => https://www.redsen.com/fr/inspired/tendances-decryptees/ledge-computing-ou-leternel-retour
7- Le cloud über alles (le cloud par dessus tout !)
Le cloud s’impose désormais partout, sa généralisation ne fait plus de doute et il se glisse même sur les sites qui résistent encore avec les logiciels d’hyper convergence !
En 2019, la tendance de l’année était l’évolution des services vers la transparence de mise en œuvre (serverless) et ça va continuer en 2020. AWS a annoncé plus de vingt nouveaux services lors de sa convention annuelle, Google ne renonce pas à concurrencer Amazon et Microsoft sur ce marché alors qu’Alibaba commence à sérieusement pointer ses serveurs dans le groupe des leaders du secteur.
 Les GAM continuent à écraser le marché du cloud…
Les GAM continuent à écraser le marché du cloud…
On le voit la concurrence ne se relâche pas sur ce marché qui est en train de devenir l’informatique à lui tout seul.
Plus sur ce sujet => https://www.redsen.com/fr/inspired/tendances-decryptees/le-shadow-it-cancer-de-la-dsi-ou-mutation-revelatrice
8- L’IA, winter is coming
2020 sera l’année de la bascule en matière d’IA. Après avoir fait le buzz pendant des années et avoir suscité les espoirs (et les craintes !) les plus fous, le soufflé va retomber, durement. On va entrer de nouveau durant une période « hivernale » où l’IA sera bien moins à la mode. Les GAFAM vont continuer à en faire, eux. Mais les autres, une bonne partie de « tous les autres » vont se calmer et se tourner vers autre chose. On va profiter de cette dernière et radicale prévision pour développer (largement) les tenants et aboutissants qui permettent de déboucher sur cette dernière prévision…
Pourquoi va-t-on vers un hiver de l’IA alors que tout le monde proclame que ce domaine a un avenir radieux ?
Et, le moins qu’on puisse dire c’est que les leaders du domaine de l’intelligence artificielle ne manquent pas d’ambition. En janvier 2018, le PDG de Google, Sundar Pichai, a affirmé dans une interview que l’IA « est plus profonde que, je ne sais pas, l’électricité ou le feu » (excusez du peu !).
Effectivement, les algorithmes de “deep learning” sont au centre du buzzword à la mode en ce moment et le nombre de chercheurs dans ce domaine aujourd’hui est environ le double du niveau observé en 2014. Mais selon François Chollet, l’une des figures de proue de la communauté du deep learning, le rythme de progression des applications d’apprentissage en profondeur ralentit significativement. Il serait même en 2019 le plus lent des cinq dernières années.
Une montée en charge vertigineuse
L’industrie de l’IA a également un problème de mise à l’échelle : il en coûte de plus en plus d’énergie (et de puissance informatique) pour former leurs modèles de plus en plus grands, avec des améliorations de moins en moins importantes (les fameux “retours décroissants”, voir plus loin).
D’après “Paris Singularity” :
Depuis 2012, la puissance informatique utilisée pour entraîner les principaux systèmes d’IA a augmenté de façon exponentielle en doublant tous les 3,5 mois (en comparaison, la loi de Moore prévoit un doublement tous les 18 mois). Depuis 2012, cet indicateur a augmenté de plus de 300 000 fois (doubler tous les 18 mois n’aurait permis de le multiplier que par 12).
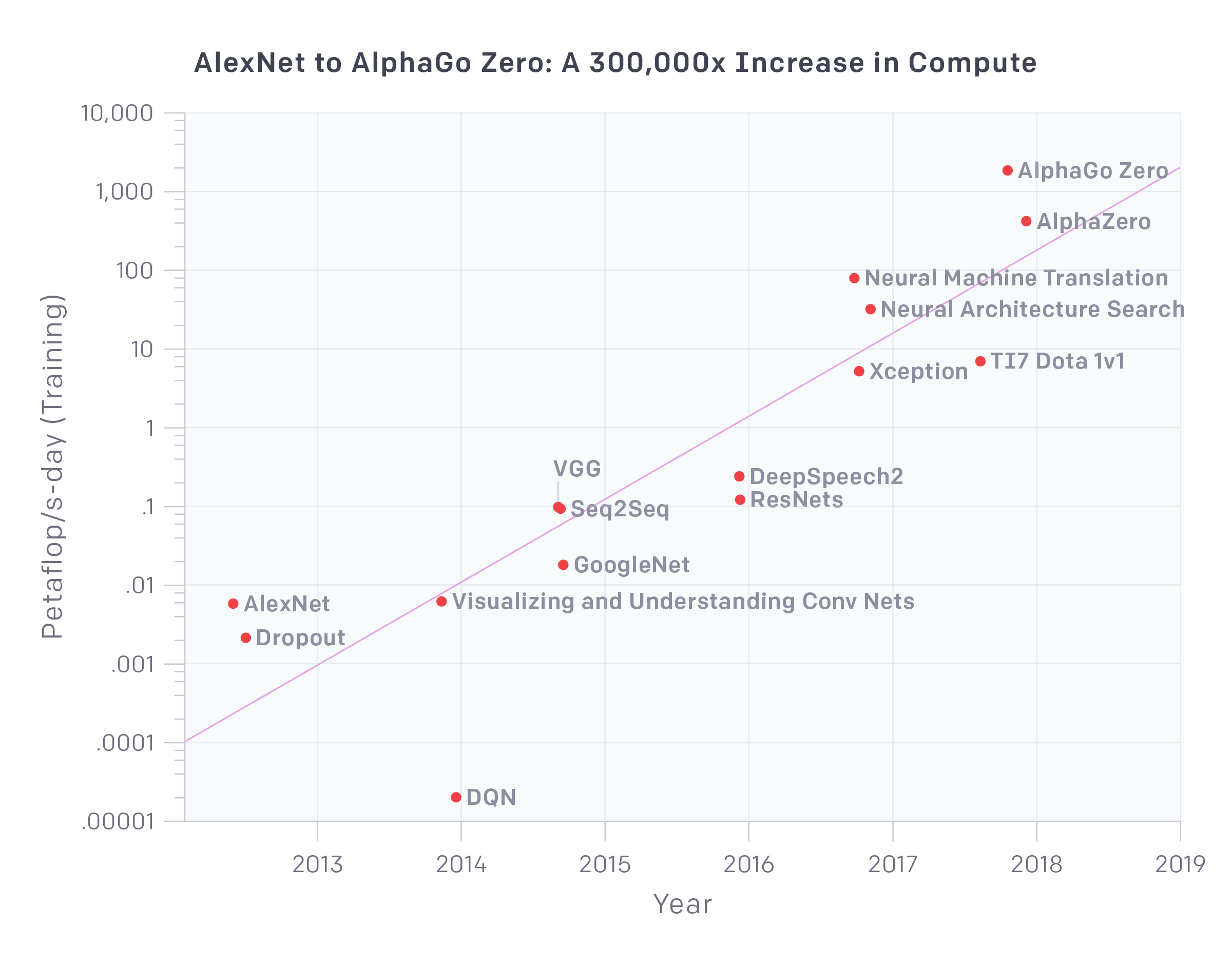
Je ne sais pas comment Paris Singularity a eu ses chiffres et comment il a calculé ces ratios mais, si c’est vrai, c’est impressionnant !
C’est avec des exemples comme celui-ci que l’on comprend que l’augmentation de la puissance de calcul a été un élément clé des progrès de l’intelligence artificielle. Cette barrière d’entrée de plus en plus élevée pourrait finir par tarir le capital-risque et l’innovation pour de projets liés à l’IA (comme lors du précédent hiver de l’IA au milieu des années 80).
Le vrai problème
Admettons qu’effectivement, les projets d’IA consomment de plus en plus de serveurs et que l’apprentissage automatique ralentisse… et alors ?
N’avons-nous pas de la puissance informatique à revendre ?
Les acteurs du cloud nous promettent des capacités sans limite et pour pas cher, autant l’utiliser avec de l’IA, non ?
Sans doute, mais ce n’est pas la seule menace qui pèse sur la primauté actuelle du machine learning. Le vrai problème, le problème crucial, ce sont les données. Le battage médiatique ambiant a beau répéter que nous vivons à l’ère du big data, ce n’est pas aussi simple comme nous allons le voir grâce à un exemple parlant. Nos “amis chinois” ont aussi leurs licornes.
La reconnaissance faciale, une spécialité chinoise
Deux startups chinoises, Megvii et SenseTime, d’une valeur respective de 4 milliards de dollars et 7,5 milliards de dollars, sont des sociétés spécialisées dans le domaine de la reconnaissance faciale. Leur application à elle seule en ferait l’une des formes d’intelligence artificielle les plus largement déployées au monde.
La Chine est LE pays de la reconnaissance faciale. Les caméras capables d’extraire les empreintes de visage des passants sont monnaie courante dans les rues des grandes villes comme Guangzhou et Shenzhen.
La nouvelle trinité
Comme la plupart des entreprises déployant des logiciels intelligents, Megvii et SenseTime s’appuient sur une technique appelée apprentissage automatique (le fameux machine learning). Ils ne demandent pas à leurs codeurs humains de programmer des ordinateurs avec des règles qui distinguent un visage et un autre. Au lieu de cela, les codeurs fournissent à l’ordinateur des masses de données sur les visages, généralement des photographies, et écrivent un logiciel qui parcourt ces photos à la recherche de motifs qui peuvent être utilisés de manière fiable pour distinguer un visage unique d’un autre. Les modèles repris par ce logiciel d’apprentissage constituent de meilleures règles pour reconnaître les visages que tout ce qu’un codeur humain pourrait décrire explicitement. Les humains savent bien reconnaître les visages, mais avec le bon logiciel, les ordinateurs peuvent apprendre à être bien meilleurs. C’est la nouvelle “trinité de l’IA” : des logiciels, des ordinateurs puissants et des données, beaucoup de données.
Des données en masse
C’est dans la troisième de ces catégories que réside le grand avantage de la Chine. Grâce à son système politique, le pays stocke et amasse de nombreuses données. Mais son avantage est plus subtil que cela. Les données à elles seules ne sont pas très utiles pour créer un logiciel d’IA. Elles doivent d’abord être étiquetées.
Pour apprendre à faire la différence entre les chats et les chiens, un système basé sur le machine learning s’entraîne d’abord sur des images dans lesquelles chaque animal est correctement étiqueté. Beaucoup d’images sont nécessaires avant que les systèmes soient capables d’afficher une performance intéressante. Pour les visages humain, c’est encore plus complexe.
Pour apprendre à faire la distinction entre le visage de deux personnes, il faut d’abord montrer à un ordinateur ce qu’est un visage, en utilisant des données étiquetées, puis comment faire la différence entre les pommettes et les sourcils, à nouveau via l’étiquetage humain. Ce n’est qu’avec suffisamment d’instructions étiquetées qu’il pourra commencer à reconnaître les visages sans l’aide humaine.
Une infrastructure numérique tentaculaire
Des entreprises telles que Megvii et SenseTime ont une infrastructure numérique tentaculaire à travers laquelle les données sont collectées, nettoyées et étiquetées avant d’être traitées dans le logiciel d’apprentissage automatique qui procède à la reconnaissance faciale. Tout comme Apple ajoute sa marque à des téléphones principalement assemblés par une main-d’œuvre chinoise bon marché, les sociétés chinoises d’IA conçoivent des logiciels et des services d’IA qui se trouvent au sommet d’une chaîne d’approvisionnement de données utilisant une main-d’œuvre bon marché dans des usines de données chinoises dont personne n’a jamais entendu parler. Megvii a dépensé 218 millions de yuans (31 millions de dollars) pour des données étiquetées au cours des trois dernières années et demie, selon son prospectus IPO. Les algorithmes utilisés par ces sociétés ne sont pas différents de ce qui est utilisé largement ailleurs. Sans l’infrastructure d’étiquetage des données de la Chine, qui est hors pair, elles ne seraient nulle part sur ce marché de la reconnaissance faciale.

Alibaba en profite aussi
Sans cette infrastructure d’étiquetage des données, les services d’IA chinois n’auraient pas décollé. Ces services d’étiquetage ont permis à Alibaba de créer un puissant service d’apprentissage automatique comme la recherche de produits basée sur l’image. Un client d’Alibaba peut prendre une photo d’un article dans une vitrine et être immédiatement dirigé vers une page où il peut l’acheter. Alibaba traite un milliard d’images comme celle-ci par jour. Il s’appuie également sur des données étiquetées pour les algorithmes d’apprentissage automatique utilisés dans ses magasins de détail, qui opèrent sous la marque Hema.
Posez-vous la question
Bref, à tous ceux qui rêvent de lancer des projets s’appuyant sur du machine learning (après tout, AWS ne propose-t-il pas tout ce qu’il faut pour cela ?), posez-vous simplement cette question (cruciale) : ai-je les données qu’il faut pour ce projet ?
Et aussi : ai-je l’infrastructure qui va me permettre d’étiqueter ces données ?
Si vous avez 10 000 malheureux dossiers à faire avaler à votre système de machine learning, passez votre chemin. Même avec dix fois plus, ça pourrait n’être toujours pas assez.
Car non-seulement il faut beaucoup de données (propres, bien étiquetées) mais il faut aussi que votre “dataset” soit bien équilibré : assez diversifié et cohérent pour éviter les biais dans les résultats. Ces éléments factuelles vont se révéler être des obstacles sérieux dans les projets d’IA des organisations plus ordinaires et moins bien dotées que les GAFAM ou les acteurs chinois spécialisés. C’est lorsque ces organisations vont réaliser que des applications basées sur les différentes variations du machine learning (apprentissage supervisé ou non supervisé, apprentissage par renforcement, etc.) sont hors de portée que l’ambiance va changer et qu’on va basculer dans un nouvel hiver de l’IA.
La prochaine victime : l’informatique quantique
Le battage médiatique va alors se tourner vers une autre technique prometteuse. On voit ce mécanisme encore utilisé actuellement à propos de l’informatique quantique avec des promesses délirantes alors qu’on n’est qu’au tout début de ce domaine radicalement nouveau (voir plus à ce propos ici => https://www.redsen.com/fr/inspired/tendances-decryptees/linformatique-quantique-pour-bientot).
Un webinaire pour aller plus loin
Nous animons un webinaire le vendredi 24 janvier à 9:00, en 45 minutes, nous passons en revue les tendances qui vont compter pour cette nouvelle année. Places limitées, inscrivez-vous ici.

Bravo pour le travail de recherche, les sources et l’éventail présenté. Bien d’accord pour sur la façon dont les tendances évoluent (progressivement) il n’y pas vraiment de rupture. Pour les voitures intelligentes, Carols Ghosn confirme ta position. Pour l’IOT c’est une tendance qui est de plus en plus répandu avec les montres connectés les enceintes intelligentes la domotique… Pour le SAAS c’est en passe de devenir un standard, c’est tellement pratique. Merci pour les autres informations ! à bientôt !