Les microservices, l’approche “serveless” et les APIs, tous ces éléments un peu abscons font parler d’eux depuis quelques années, cela n’a pu vous échapper. Cependant, il ne s’agit pas d’une tendance à la mode réservée aux seuls développeurs “full stack” et “devops”. Il s’agit bel et bien d’une approche rationnelle pour faciliter les développements d’applications…
L’intérêt de l’approche microservice
Imaginons que vous ayez à développer une nouvelle application qui doit, entre autres, vérifier la validité des numéros de téléphones saisis. Ou alors vérifier la validité des adresses emails saisies. Bien sûr, vous pouvez coder cela en partant de zéro ou bien utiliser à la place un des nombreux microservices qui sont disponibles sur le net et qui font cela très bien avec un simple appel de type GET (HTTP).
D’accord pour le microservice spécialisé mais comment le trouver ?
En faisant des recherches, on tombe rapidement sur ce genre d’articles qui liste plusieurs API dédiées à la vérification de numéros de téléphone… https://geekflare.com/fr/phone-number-validation-api/
Ensuite, on peut aller sur le site de chacune afin de se faire une idée, comme celui de phone-validator https://www.phone-validator.net/
Les marketplaces d’API !
Une autre approche plus rationnelle et plus efficace est d’utiliser une marketplace dédiée aux API justement !
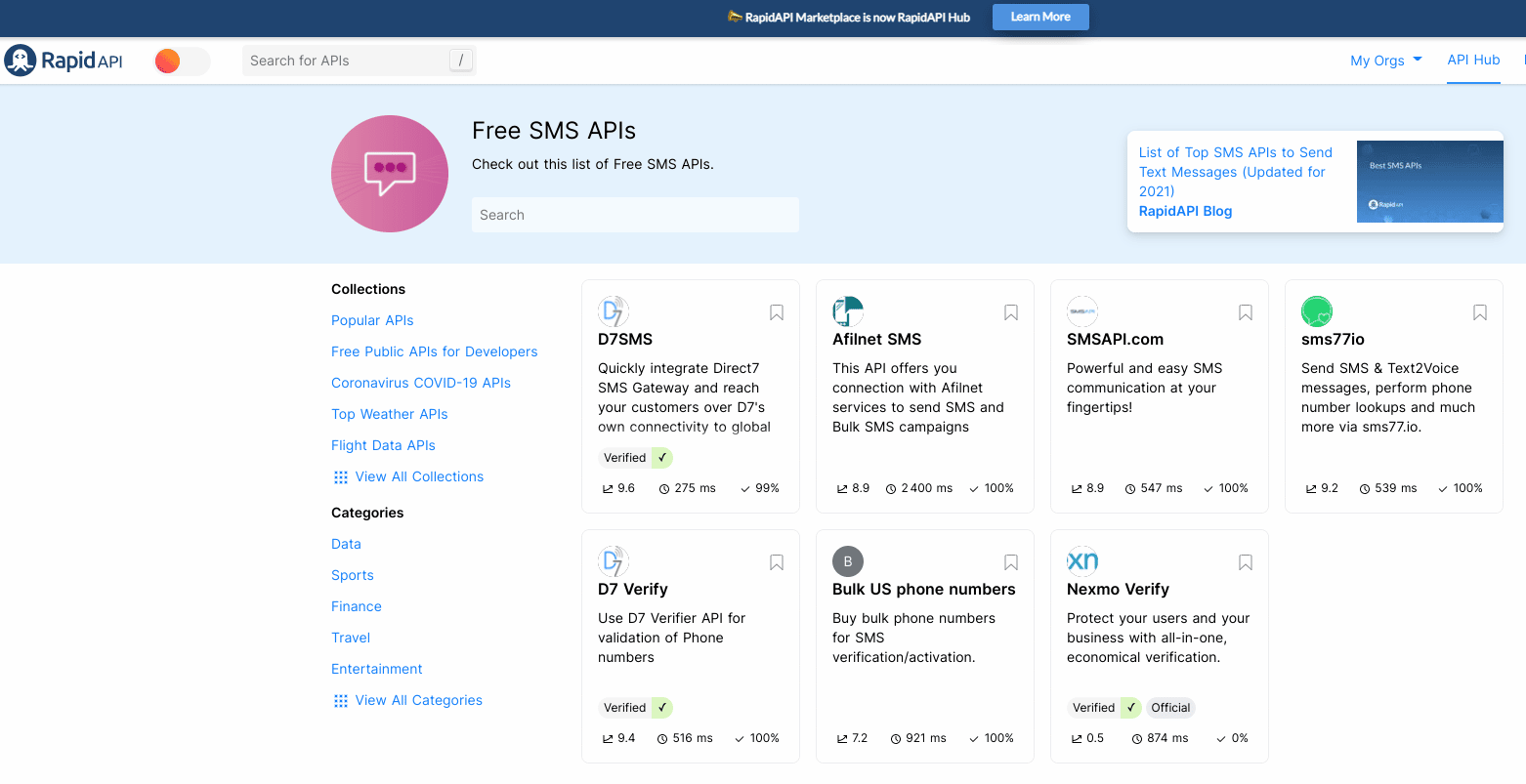
Et il se trouve qu’il y en a désormais plusieurs… Un site comme RapidAPI regroupe des milliers de microservices accessibles par les API courantes comme REST. Pour comprendre l’intérêt d’avoir recours à ces APIs, prenons pour exemple l’API REST de Wikipédia qui est très complète et bien documentée. Elle permet de nombreuses opérations différentes, notamment sur les pages (créer, éditer, supprimer une page, changer sa langue etc.) et sur les comptes (créer, bloquer, éditer un utilisateur et ses permissions etc.). Il s’agit d’une API publique accessible via le protocole HTTP (extrait de l’excellent article https://practicalprogramming.fr/api-rest). Nous pouvons donc y faire des appels et lire les réponses directement depuis notre navigateur web. Pour revenir à RapidAPI, sur la page https://rapidapi.com/collection/free-sms-apis on trouve une douzaine de microservices permettant de vérifier des numéros de téléphone et celles-ci sont gratuites !
Dans cet autre article https://geekflare.com/fr/sell-apis/, Amrita Pathak explique (plutôt bien) pourquoi les marketplaces dédiées aux API sont à la mode en ce moment… extraits :
Quels sont les avantages d’un marché d’API ?
Pour les fournisseurs d’API :
- L’exposition plus large augmente votre base d’utilisateurs.
- Il vous aide à mesurer la demande actuelle du marché.
- Fournit un forum interactif où les éditeurs peuvent recevoir des commentaires sur leurs API de la part des développeurs en termes de convivialité, de performances, etc.
- Les fournisseurs d’API peuvent obtenir tout le guide pédagogique sur la façon de publier leurs API avec des événements en ligne
Pour les développeurs :
- Trouver des API devient plus facile avec de nombreux choix, catégories, fourchettes de prix, etc.
- Ils peuvent rapidement parcourir pour voir toutes les API disponibles actuellement avec leurs fonctionnalités.
- Les consommateurs peuvent également trouver des API performantes grâce à des classements, des statistiques et des tableaux.
- Les forums leur permettent de vérifier les critiques d’une API par d’autres développeurs, ce qui les aide à choisir une API de qualité.
- Les événements en ligne, les guides pédagogiques et la documentation les aident à utiliser l’API efficacement.
Effectivement, il est plus facile de trouver le bon service sur RapidAPI que de chercher au hasard de ce que va vous renvoyer votre moteur de recherches préféré. Ces marketplaces sont nombreuses mais il y en a de moins en moins qui restent indépendantes car ce marché a été plutôt “agité” ces dernières années. En effet, les acquisitions se sont multipliées avec Mulesoft passé sous la coupe de Salesforce pour un montant de 6,5 Md$, Layer 7 racheté par CATechnologies, 3scale par Red Hat, Vordel par Axway, Apigee par Google, Mashery par Intel puis Tibco, les Français de Restlet par Talend, Boomi par Dell, Apiphany par Microsoft… ça fait beaucoup !
Voici donc une courte liste des plateformes du marché pour l’intégration via microservices et API :
https://rapidapi.com/products/hub/
https://english.api.rakuten.net/api-providers
https://promptapi.com/provider

Serverless et FaaS
L’accès à des microservices à travers des API a évidemment débouché sur une abréviation liée aux services disponibles sur le cloud : La fonction en tant que service ou FaaS.
La fonction en tant que service est une catégorie de services de cloud computing qui fournit une plate-forme permettant aux clients de développer, d’exécuter et de gérer des fonctionnalités d’application sans la complexité de créer et de maintenir l’infrastructure généralement associée au développement et au lancement d’une application. La création d’une application suivant ce modèle est un moyen d’obtenir une architecture serverless, et est généralement utilisée lors de la création d’applications utilisant des microservices.
On associe bien souvent l’abréviation FaaS au concept “serverless”… de quoi s’agit-il ?
L’informatique sans serveur dans les termes les plus élémentaires est le développement et le déploiement d’applications sans se soucier des serveurs. L’informatique sans serveur tire parti du cloud en fournissant l’infrastructure (les serveurs et les outils) nécessaires pour créer et déployer des applications modernes par les développeurs.
À la base, l’informatique sans serveur permet aux développeurs d’écrire et de déployer des codes sans se soucier de l’infrastructure sous-jacente. Il s’agit d’une mise à l’échelle automatique, ce qui signifie que les clients sont facturés en fonction du calcul – le temps d’exécution du code (pay as you use) – et non sur une quantité fixe d’utilisation du cloud.
L’architecture serverless est donc un modèle dans lequel le fournisseur de services cloud (AWS, Azure ou Google Cloud par exemple) est responsable de l’exécution d’un morceau de code en allouant de manière dynamique les ressources (sans qu’il y ait besoin de réserver et de paramétrer un serveur à l’avance donc, d’où le nom… CQFD). Et il ne facture que la quantité de ressources utilisées pour exécuter le code. Le code est généralement exécuté dans des conteneurs sans état pouvant être déclenchés par divers événements, notamment des requêtes http, des événements de base de données, des services de file d’attente, des alertes de surveillance, des téléchargements de fichiers, des événements planifiés (tâches cron), etc.
Ce concept repose donc sur le concept d’abstraction puisque les développeurs ne connaissent pas l’infrastructure sur laquelle le serveur s’exécute.
Avantages de l’informatique sans serveur
- Économique — les développeurs et les utilisateurs ne paient que pour le temps d’exécution du code sur une plate-forme de calcul sans serveur. Vous n’avez pas à payer pour des machines virtuelles inactives.
- Autoscaling — la fourniture de services via une architecture sans serveur signifie que la mise à l’échelle est gérée par le fournisseur de cloud pour vous. Vous ne payez que pour le temps de calcul, et en cas d’augmentation de la demande pour le service, le fournisseur gère la mise à l’échelle ou la réduction lorsque le code n’est pas en cours d’exécution.
- Augmentation de la productivité des développeurs, car du temps sera consacré à la tâche principale d’écriture et de développement d’applications, au lieu de bricoler avec les serveurs et les environnements d’exécution.
- Avec serverless, les développeurs n’ont pas besoin de spécifier ou de configurer des machines virtuelles sur le cloud.
Inconvénients de l’informatique sans serveur
- Verrouillage du fournisseur — Il existe une forte possibilité de différences dans la fourniture de services sans serveur d’un fournisseur à un autre. Il est donc difficile de changer de fournisseur de cloud.
- Latence — retard dans le temps nécessaire pour exécuter une fonction sans serveur pour la première fois, souvent appelé démarrage à froid (un point qui n’est pas à négliger…).
- Difficulté de débogage et d’exécution des tests, car les développeurs sont isolés de l’infrastructure et des outils du serveur principal.

Ne vous y trompez pas, l’informatique sans serveur n’implique pas l’absence de serveurs. Il s’agit cependant de fournir une infrastructure de serveur cloud pour permettre aux développeurs d’écrire et de faire fonctionner ces programmes comme une fonction sur un serveur fourni dans le cloud.
Les développeurs peuvent ainsi se concentrer uniquement sur leur responsabilité principale d’écrire des codes et ne payer que pour le temps d’exécution du code sur une architecture sans serveur. Cela signifie que les développeurs doivent se préoccuper de la livraison du service et non du mécanisme ou de l’outillage de livraison. Cependant, n’oublions pas que les promesses de type “vous n’avez pas à vous en soucier” peuvent contenir de nombreux pièges et nous avons vu dans la chronique Les “cloud management platforms”, compléments utiles de votre gestion multicloud que l’usage du cloud exigeait d’être suivi et géré de près…
Une approche à la mode
Avoir recours aux microservices et au APIs est tellement dans le vent en ce moment que certains prestataires en ont fait le cœur de leur offre, y compris du côté des sociétés de services. Pour illustrer cette tendance, j’ai interrogé Maxim Topolov de Code.store qui est justement pile dans ce positionnement… Vous allez voir que ces réponses sont riches d’enseignements sur les tendances actuelles !
Q- Peut-on dire que vous agissez comme une société de services mais spécialisée dans la réalisation de « connecteurs » ?
R- Absolument, nous développons pour le compte de tiers des connecteurs, plug-ins ou systèmes d’import de données en masse.
Q- Quels sont vos clients (sans entrer dans le spécifique, les noms ne sont pas nécessaires) ?
R- Nous travaillons essentiellement avec les éditeurs logiciels SaaS, leur permettant de déléguer la création des intégrations avec d’autres outils plébiscités par leurs clients. Pour certains, nous développons de véritables plug-ins ou extensions de leur fonctionnalités (exemple: un module d’agenda et calendrier pour un outil de communications critiques). Enfin nous intégrons et connections aussi les outils no/Low-code pour les clients finaux. Essentiellement des grands groupes.
Q- Réalisez-vous seulement les connecteurs ou les mettez-vous en place également (au sein des systèmes du client… prestation d’intégration de systèmes donc) ?
R- Nous intégrons avec plaisir de nombreux outils. Notre credo est de pouvoir mettre en place des plate-formes digitales (e-commerce, apps métier,…) bout en bout sans coder. Ou très peu. Utilisant la myriade d’outils modernes : Airtable, Hevo, Bubble, Retool, etc.
Q- « nous développons pour le compte de tiers des connecteurs, plug-ins ou systèmes d’import de données en masse », quelles sont les proportions respectives des domaines applicatifs concernés ?
R- Disons 30/40/10 les 20% restant étant les projets d’intégration bout en bout.
Q- En clair, quel % de transactionnel, de E-commerce et de big data (ou autres non-cités ici) ?
R- Le transactionnel 80% et le 20% d »ecommerce, on fait pas de big data per se.
Q- Vous arrive-t-ils d’utiliser des plate-formes de « middlewares internet » comme Zapier ou autre (comme Tray.io ou autres) ?
R- Zapier plus rarement, même si cela nous arrive de développer des « zaps », les gens viennent nous voir car, justement Zapier n’est plus adapté à leur situation. Souvent à cause de complexités particulières du projet de connectique. Pas tray.io non plus mais nous utilisons des plateformes similaires comme integromat.
Q- « Enfin nous intégrons et connections aussi les outils no/Low-code pour les clients finaux », quels sont les outils que vous rencontrez ?
R- On travaille beaucoup avec Shopify Plus, Retool, Stripe, Mailchimp, Airtable, Bubble. Beaucoup de Hubspot et de CMS du type GraphCMS ou Contentful.
Q- Combien êtes-vous de développeurs dans votre équipe ?
R- Nous sommes 20 experts pour le moment, mais grossissons rapidement.
Q- « Nous travaillons essentiellement avec les éditeurs logiciels SaaS », quels sont-ils ?
R- Par exemple, Team On The Run est un client important pour lequel nous avons développé plusieurs plugins. (https://www.streamwide.com/fr/team-on-the-run/) Ou encore PageProof (https://pageproof.com/) que nous avons intégré avec ClickUp.
Q- Dans vos clients « grands groupes », êtes-vous affecté à des opérations de « reprise d’applications issues du shadow IT » ?
R- Pas vraiment, nous sommes de plus en plus sollicités par les départements IT pour concourir face à des sociétés de services plus classiques, développant des solutions sur mesure partant de frameworks (.NET / PHP Symfony ou Drupal, NodeJS). Ils viennent nous voir car nous pouvons sortir des projets d’envergure en quelques semaines et pour quelques dizaines de milliers d’euros VS des mois / des centaines de K€ pour les projets « à l’ancienne ».
Ce qui est intéressant c’est la maturité soudaine des plateformes no-code / low-code acquise ces deux dernières années. Les boîtes comme Bubble, Airtable ou Retool sont très bien financées et ont aujourd’hui une palette de fonctionnalités et une robustesse qui devient supérieure à ce qu’on peut obtenir avec des projets faits maison.
Q- En lisant vos réponses, je me suis dis que, finalement, la vague des outils low code/no code vous avait été très profitable, je me trompe ?
R- Absolument. La multiplication des outils no-code / low-code nous a été très favorable. D’ailleurs c’est même la raison pour laquelle après avoir vendu mon agence il y a trois ans j’ai remis le couvert. Je pense que l’opportunité est immense et on n’est qu’au début de la vague. Il reste une quantité phénoménale de processus à digitaliser, qui se prêtent mal aux développement sur mesure pour des raisons de ROI faible. Gros marché, faibles marges, mais je pense qu’il y a de la place pour des acteurs comme nous à la limite entre conseil (choix des outils, conseil en management, conduite du changement et formation) et intégration (configuration et adaptation des outils, leur connexion).
Q- Est-ce qu’on peut en dire autant de la vague cloud ?
R- Pas vraiment. La vague cloud a surtout transformé en profondeur les « hébergeurs » qui de rentiers sont passés à de la prestation de service. Le virage a été destructeur pour certains ou très bénéfique pour d’autres. Mais le développement a peu été impacté par le cloud, si ce n’est par la simplification des outils de déploiement.
Q- Pour être plus clair, est-ce que code.store aurait eu le même succès sans ces deux facteurs (no code et cloud) ?
Code.store n’existerait pas. Car nous l’avons créé (en 2020) parce qu’il y a justement cette vague.
Q- Enfin, pour revenir sur la question des API, j’imagine que vous appuyez vos travaux sur du REST mais, là encore, c’est un acronyme qui couvre un vaste domaine !
Pouvez-vous m’apporter quelques précisions sur votre usage de REST (via HTTP ou autres ?) ?
R- REST est le protocole absolument dominant aujourd’hui. Toutes les API de tous les produits que nous intégrons sont en REST. Mais un nouveau venu depuis quelques années commence à prendre beaucoup de place : GraphQL. C’est pour moi l’avenir des API. GraphQL résout beaucoup de problèmes du REST (manque de typage, overfetching, underfetching, manque de flexibilité…).
Les effets de la vague cloud+NoCode
Les réponses de Maxim Topolov confirment un changement en cours : la combinaison du cloud avec les outils NoCode et la généralisation de l’usage des microservices est en train de changer nos pratiques du développement d’applications pour les entreprises.
Terminé de tout écrire à partir de zéro, fini les projets interminables et le mépris vis-à-vis des “outils pour amateurs” : le NoCode est en train d’impacter le développement en profondeur et ce n’est sans doute que le début !
Cependant, n’allez pas en déduire que les microservices sont la solution idéale et qu’il faut les mettre à toutes les sauces. En effet, eux aussi présentent leur lot de défauts : complexité de l’architecture, difficulté du debugging et difficulté d’avoir un état de la plate-forme d’exécution à tout moment. Bref, ils sont à utiliser avec discernement, pas partout et pas tout le temps.