En ce moment, HP, Microsoft et Cisco sont d’accord sur un point : l’edge computing, voilà l’avenir !
Allons bon, qu’est-ce c’est que c’est encore que ça ?
Si vous n’avez pas encore entendu parler de cette nouvelle mode, rassurez-vous, vous n’êtes pas les seuls. J’ai mis quelque temps à comprendre de quoi il s’agissait et pourquoi ces grands acteurs s’y intéressaient tant…
 Une définition compréhensible par tous
Une définition compréhensible par tous
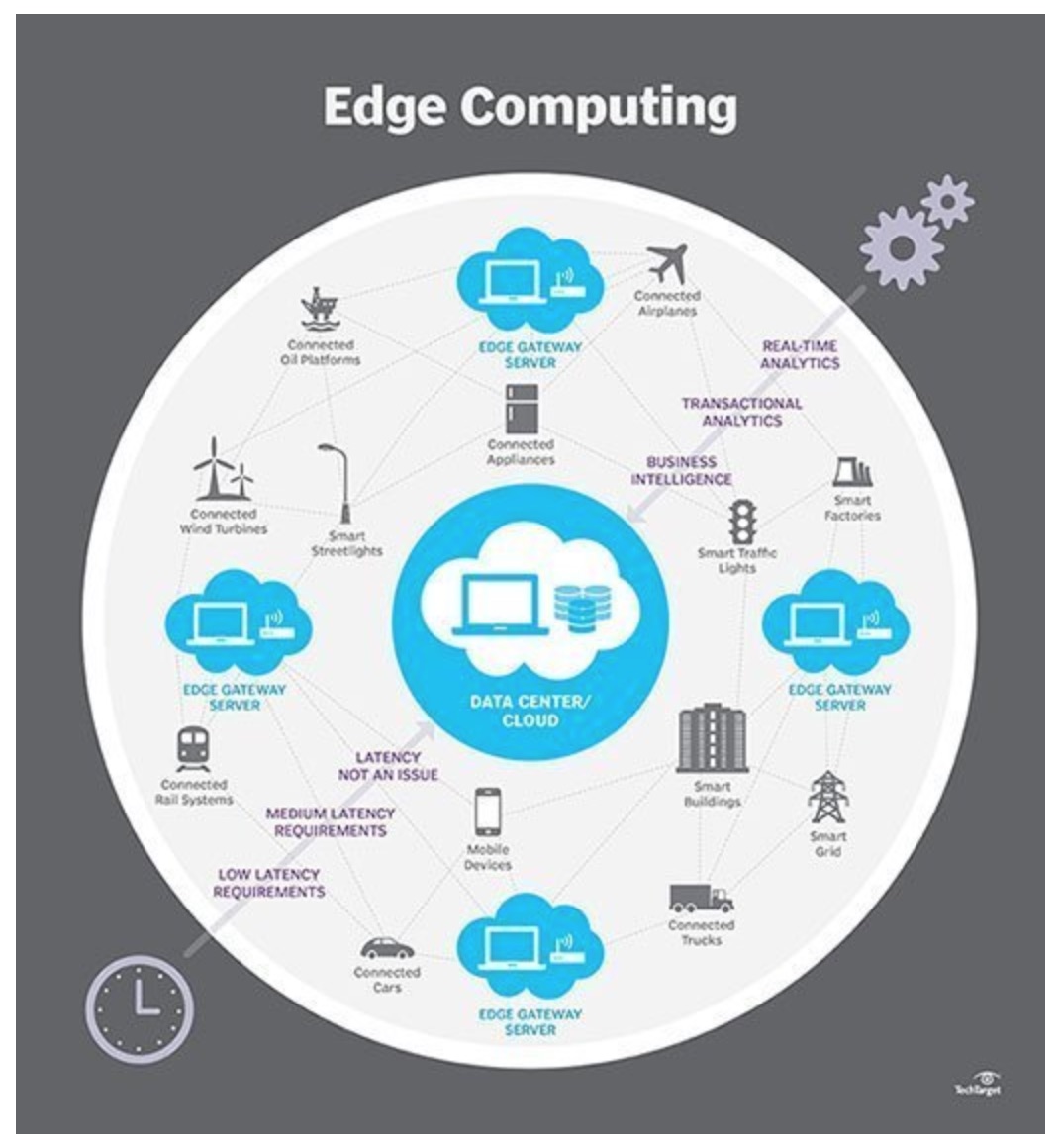
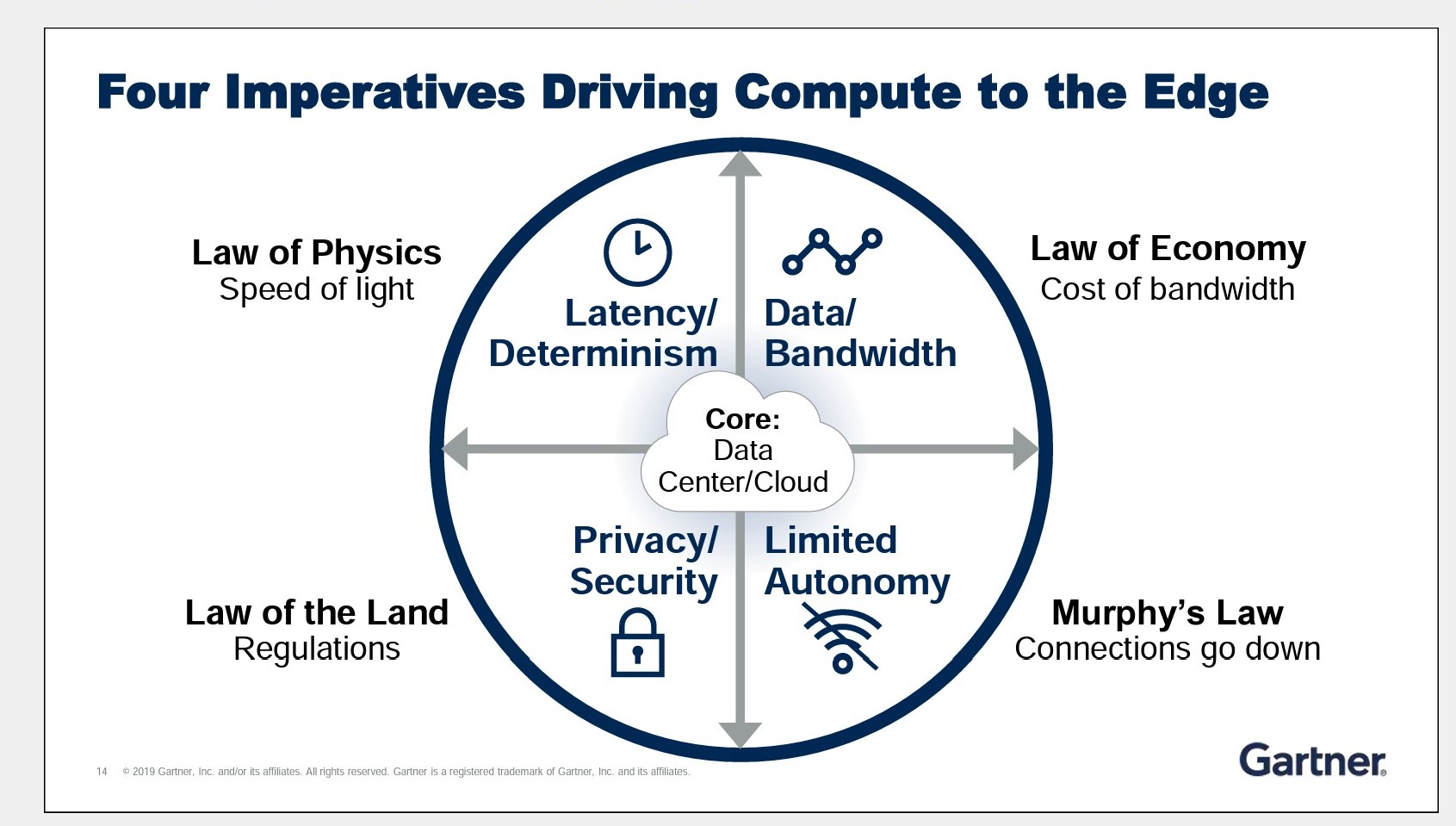
Alors, commençons par nous mettre d’accord sur une définition simple et compréhensible par tous. “Edge computing” est tout d’abord lié à l’Internet des objets (que nous avons examiné dans une précédente chronique, voir à https://www.redsen.com/chronique-alain-lefebvre/iot-linternet-des-objets-vers-un-nouveau-boom/. L’argument est le suivant : dans certaines conditions d’application, il faut minimiser la latence (c’est-à-dire le temps de transfert réseau et donc, le temps de réponse global) pour garder de bonnes performances. Dans ce cadre, il serait plus logique de traiter localement les données recueillies par les capteurs plutôt que de les expédier directement dans le Cloud. En général, on estime qu’il faut entre 150 et 200 millisecondes pour transmettre les données d’un dispositif IOT à un fournisseur de services cloud et inversement. Alors qu’avec des serveurs déployés à proximité de ces dispositifs (On the edge -sur le bord- donc…), ce délai pourrait être de l’ordre de deux à cinq millisecondes. Un gain très intéressant (presque cent fois mieux !) si la performance est un facteur critique. L’edge computing est aussi appelé “mesh computing” (informatique en réseau maillé), “peer-to-peer”, “informatique autonome”, “grid computing”, et par d’autres noms (fog computing, dew computing, etc.) qui impliquent tous la gestion informatique décentralisée par opposition au cloud computing qui lui représente le nouveau paradigme de l’informatique centralisée.
Gartner y croit beaucoup
D’après le célèbre cabinet Gartner, l’Edge computing représente forcément une tendance lourdes de ces prochaines années. Les consultants du Gartner font reposer leur raisonnement sur deux éléments fondamentaux : le “data flip” d’une part et les contraintes techniques et économiques d’autre part.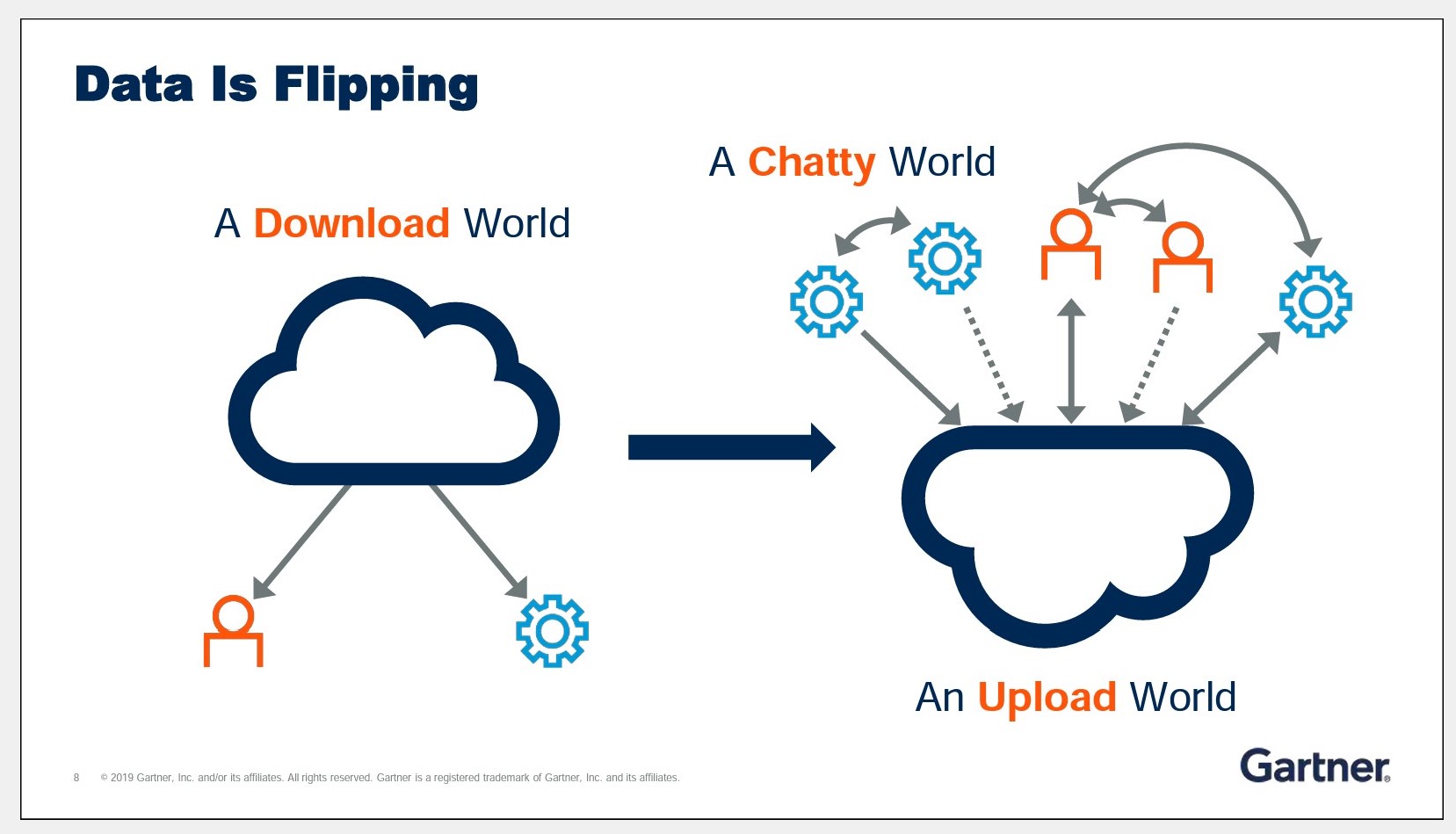
Le data flip
D’après le Gartner, notre usage du réseau est en train de changer, en profondeur. Nous sommes passés d’un mode plutôt unidirectionnel où nous récupérions des données depuis le cloud (a download world…) à un mode beaucoup plus bidirectionnel où les objets conversent sur le réseau entre eux et vers le cloud (an upload world).
Des contraintes structurantes
Ensuite, les consultants du cabinet pensent que les différentes contraintes qui vont peser sur les réseaux vont nous inciter à traiter les données localement avant de les faire remonter vers le cloud.
Tout cela n’est pas faux mais cela sera-t-il suffisant pour nous faire revenir en arrière, nous faire basculer vers l’Edge Computing plutôt que de continuer à tout mettre dans le cloud ?
L’Edge Computing, juste un buzzword de plus ?
Dans le tourbillon des modes technologiques que nous vivons (et subissons !) en permanence, toutes ne se valent pas. Dernièrement, j’ai eu l’occasion de vous dire mes doutes la blockchain (voir à https://www.redsen.com/chronique-alain-lefebvre/il-est-temps-de-se-montrer-enfin-raisonnable-vis-a-vis-de-la-blockchain/) ou de vous prévenir que la nouvelle vague de l’IA ne pouvait pas se généraliser (et donc débouchera forcément sur un nouvel “hiver de l’IA” comme il y en a déjà eu plusieurs dans son histoire, voir à https://www.redsen.com/chronique-alain-lefebvre/remettons-les-choses-a-leur-place-en-matiere-dintelligence-artificielle/). C’est notre rôle, ici, dans ces chroniques, de vous donner un éclairage honnête sur ces tendances, faire le tri entre celles qui sont significatives et celles qui ne sont que le fruit du battage médiatique perpétuel que les grands acteurs ne peuvent s’empêcher de produire.
Or, il s’avère qu’il y a encore beaucoup de confusion autour de cette notion d’Edge Computing qui est assez floue. Pour certains (dont le Gartner) même la moindre sonde local dotée d’un peu d’intelligence entre dans la définition de ce nouveau paradigme… Avec une approche aussi large, il sera effectivement difficile d’échapper à l’essor du Edge Computing !
La réalité la plus probable, c’est que cette nouvelle mode n’annonce pas le retour des serveurs sur vos sites car la poussée vers le cloud est désormais trop forte pour s’inverser à court terme.
Donc, inutile d’attendre trop de ce “Edge computing” qui ne va concerner que quelques contextes applicatifs spécifiques (par exemple les sondes de la solution d’Hacknowledge – https://www.redsen.com/rgpd/meet-up-fintech-rencontre-hacknowledge/), rien qui justifie d’en faire une nouvelle tendance structurante.
Une bouée de sauvetage pour les fournisseurs
Mais alors, si l’Edge Computing n’est pas aussi important que le prétend le Gartner, pourquoi donc des acteurs importants comme Microsoft, HPE, Cisco et d’autres mettent-ils leurs poids dans cette balance illusoire ?
Pour le comprendre, il faut revenir sur le développement du marché du cloud ces dernières années. Pour beaucoup de ces acteurs traditionnels, ce développement rapide et cette généralisation ont représenté une surprise, une mauvaise surprise. HPE vend forcément moins de serveurs et Cisco moins de routeurs si les entreprises préfèrent s’appuyer sur l’offre Cloud d’Amazon et d’OVH plutôt que de continuer à développer leurs propres infrastructures (qui, vous l’aurez compris, nécessitent toujours plus de serveurs et d’équipements réseau). Ce n’est pas par hasard que Xerox et HP discutent de fusion en ce moment (pour compenser la baisse des ventes, la concentration est le remède habituel). Et comme c’est ce qui est arrivé, les acteurs traditionnels se sont retrouvés en crise…
Et l’idée pour sortir de cette crise, c’est de lancer une nouvelle mode. D’où la soudaine popularité de l’Edge computing qui est soutenue, pas de façon tout à fait innocente, par certains acteurs (pas tous). Ce n’est pas la première fois que les grands acteurs tentent de lancer une nouvelle mode technique. C’est d’ailleurs à ça qu’on reconnait les vrais acteurs des simples fournisseurs : les premiers ont assez d’influence sur le marché pour l’orienter (et ils ne se privent pas de le faire à leur avantage) alors que les seconds se contentent de suivre les tendances. Et le fait est que, depuis quarante ans (oui, quarante ans !), ces modes techniques se sont succédé (des dizaines !).
Un cycle qui se répète
Et depuis quarante ans on constate que le seul point commun entre ces modes, c’est l’oscillation des mouvements d’architecture système alternant décentralisation et recentralisation.
Premier round : mini vs mainframe
Tout cela a commencé avec les mini-ordinateurs qui proposaient de briser l’hégémonie des mainframes en apportant leur capacité de traitement au niveau départemental (un premier niveau de décentralisation). Cette nouvelle possibilité, beaucoup moins coûteuse que les mainframes, a fait la fortune d’HP, mais surtout de DEC (Digital Equipment Corporation qui a été un moment N°2 mondial derrière IBM et qui a depuis disparu, racheté par Compaq lui-même englouti par HP…). Toutefois, tenter de faire fonctionner tous ces minis en réseau (la proposition de DEC justement, qui était très en pointe dans le domaine du fonctionnement en réseau, et ce dès les années 70) s’est avéré aussi compliqué et coûteux que de tout mettre sur un gros mainframe. Premier retour en arrière donc.
 Seconde manche : au tour des PC de secouer le statu quo
Seconde manche : au tour des PC de secouer le statu quo
Puis, les PC sont arrivés, ont déferlé et ont tout changé (années 80 et 90). Tout d’un coup, les organisations installaient plus de micro-ordinateurs qu’elles ne l’avaient jamais fait avec les terminaux passifs. Cette profusion de PC poussait à en faire toujours plus avec eux. Et, à l’époque, seul le modèle client-serveur permettait de développer des applications sur PC qui allaient fonctionner correctement en réseau. Je me souviens particulièrement bien de cette époque puisque je peux dire que j’ai participé à la promotion du client-serveur autant que j’ai pu (j’ai rédigé et publié trois livres sur le sujet, entre autres). Le client-serveur semblait représenter la bonne alternative à l’architecture centralisée, apportant enfin la dimension distribuée à nos applicatifs sans que ça soit trop compliqué à développer.
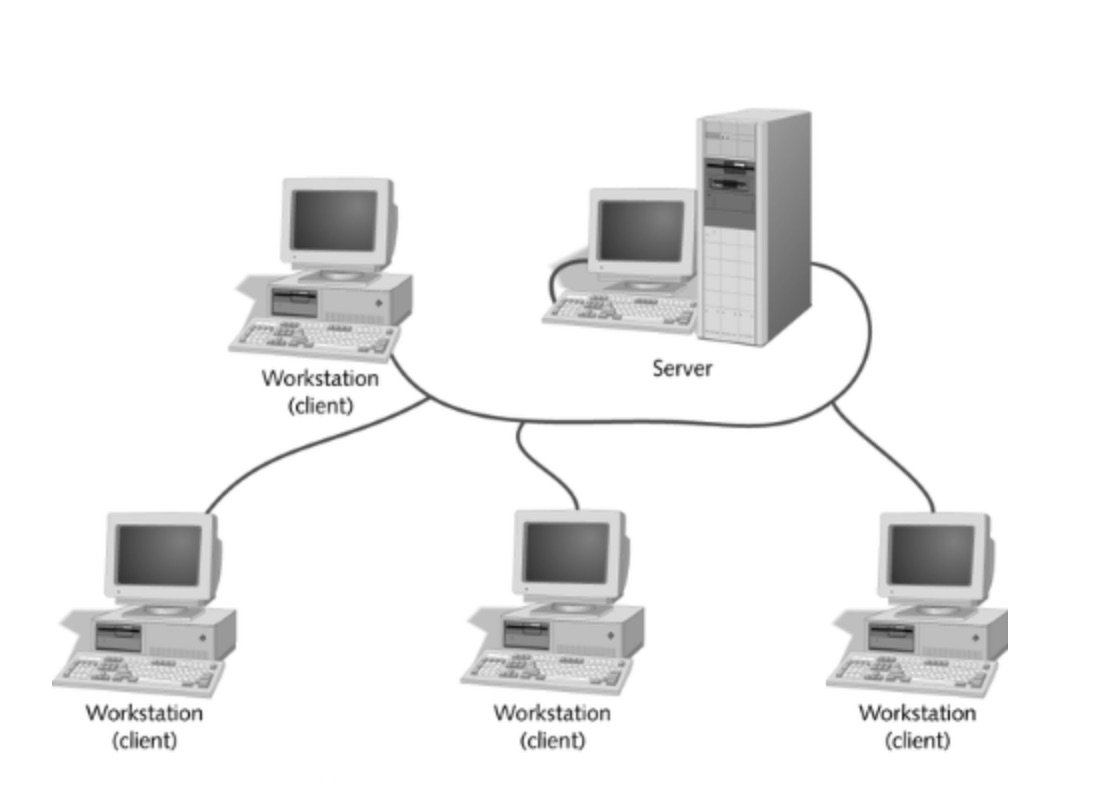 Le mur du déploiement fait chuter le client-serveur
Le mur du déploiement fait chuter le client-serveur
Mais justement, le problème avec le client-serveur ne se situait pas au niveau du développement mais plutôt au niveau de l’administration, et ce dès le déploiement des applications. La généralisation de Windows sur les postes de travail a exacerbé cette lacune sur le plan du déploiement/administration à tel point que les solutions proposées par Citrix connurent un certain succès, car elles permettaient de “recentraliser” le déploiement de Windows et son administration sur des postes de travail simplifiés (des PC dépourvus de stockage en local). Une fois de plus, on constatait un certain retour en arrière après les grands espoirs suscités par le client-serveur.
Le cloud triomphe sur tous les fronts (mais cela a pris presque vingt ans…)
La suite de cette histoire, vous la connaissez déjà : l’essor du Cloud et des applications hébergées (initié par Hotmail, continué par Salesforce et disponible pour pratiquement tout désormais) a concrétisé un énième mouvement en faveur de la centralisation.
Aujourd’hui, il me paraît très improbable que l’Edge computing réussisse à détrôner (ou même simplement à se faire une place significative à côté) le cloud comme architecture de référence pour nos applications et même pour l’IOT. Tout simplement parce que le problème de l’administration distribuée n’est toujours pas adressé de façon satisfaisante.
Pourquoi le cloud a-t-il connu un tel succès au bout du compte ?
La question clé de l’administrabilité
Eh bien justement parce que les outils d’administration sont légion pour accompagner les projets (on pense à Kubernetes, Proxmox et à d’autres où on note une grande proportion de solutions open source d’ailleurs…). Et pourquoi cette offre primordiale et indispensable est-elle abondante ?
 Tout simplement parce que les serveurs du cloud sont quasiment tous sous Linux (hum, peut-être pas chez Microsoft !). Et c’est justement la primauté de cette plateforme qui a favorisé les développements et la popularité de ces outils incontournables. Or, l’Edge computing semble favoriser un retour à la diversité des plateformes qui rend l’administration ingérable. Et pourtant, même si la question de l’administration est importante, ce n’est pas peut-être pas là que se situe le vrai talon d’achille de l’Edge computing…
Tout simplement parce que les serveurs du cloud sont quasiment tous sous Linux (hum, peut-être pas chez Microsoft !). Et c’est justement la primauté de cette plateforme qui a favorisé les développements et la popularité de ces outils incontournables. Or, l’Edge computing semble favoriser un retour à la diversité des plateformes qui rend l’administration ingérable. Et pourtant, même si la question de l’administration est importante, ce n’est pas peut-être pas là que se situe le vrai talon d’achille de l’Edge computing…
La question critique de la sécurité
Et si l’Edge computing posait de façon accrue la question de la sécurité ?
Si on croit, comme Mikko Hyppönen, que “si c’est intelligent, c’est vulnérable”, alors rapprocher les capacités de traitement au plus près des capteurs semble ouvrir en grand la vulnérabilité des systèmes fortement distribués. Mikko Hyppönen est un expert reconnu en cybersécurité et il est aussi directeur de la recherche de F-Secure. « Ce qui se passe en ce moment autour de nous pourrait être comparé à l’amiante, mais dans l’informatique… », a déclaré le finlandais, « … une grande innovation qui, des décennies plus tard, s’est avérée comme la pire des innovations ».
Voyons ce que nous dit Mikko sur la question de la sécurité de l’IOT :
Alors, bien sûr, à la lumière de cet avertissement radical, il semble plus raisonnable (et surtout plus sûr !) de laisser les serveurs à l’abri dans le cloud (derrière des firewalls bien gérés, c’est mieux) plutôt que “on the edge” et (très) vulnérables.
La question de la sécurité a toujours été présente dans l’histoire de l’informatique mais c’est vraiment depuis que l’Internet a pris toute sa place que cette question est devenue tout à fait critique. En effet, avec l’internétisation croissante de l’informatique met la dimension réseau en premier et avec elle, le contrôle des accès ne peut plus être négligé.
Un développement concentrique
Le développement actuel de l’IOT est en train d’ajouter un cercle de plus à notre “paysage informatique”. Depuis quarante ans, il en va ainsi : l’informatique se développe en concernant toujours plus de gens (et de choses désormais !) pour des usages toujours plus larges et diversifiés. Nous aurons donc une partie de l’intelligence (comprendre les traitements de base sur les données recueillies) qui va se situer localement (on the edge) mais cela ne va pas modifier en profondeur la tendance actuelle en faveur du Cloud.
On centralise pour maîtriser
Centraliser la majeure partie des traitements sur les serveurs du cloud est toujours la seule façon de les rendre gérables et sécurisés à terme. Les changements mainframe -> client/serveur -> Web reflètent l’évolution des technologies dans un contexte de compromis entre 1) confort et fonctionnalité utilisateur, 2) facilité d’administration et 3) limites du réseau.
Ajouter des nouvelles couches paraît facile au début, mais comme nous l’a montré la dure leçon du client-serveur, faire en sorte que tout fonctionne en harmonie et avec un niveau de sécurité acceptable, c’est une toute autre affaire et c’est bien ce critère qui, au final, fait le tri entre ce qui s’installe durablement dans le paysage et ce qui ne fait que passer comme une mode éphémère.